RynnVLA-001 Using Human Demonstrations to Improve Robot Manipulation
RynnVLA-001: Using Human Demonstrations to Improve Robot Manipulation

I. 核心思想与贡献
RynnVLA-001 的核心贡献在于提出了一套系统性的知识迁移方法论,旨在解决机器人领域长期存在的数据稀缺问题。它不直接创造一个全新的模型架构,而是通过一个精心设计的渐进式预训练流程,将海量、易于获取的人类第一视角视频中蕴含的通用物理世界知识,高效地迁移到需要精确控制的机器人操作任务上。其本质是为 VLA 模型提供一个极其优越的“热启动”权重,从而大幅降低对昂贵的机器人示教数据的依赖。
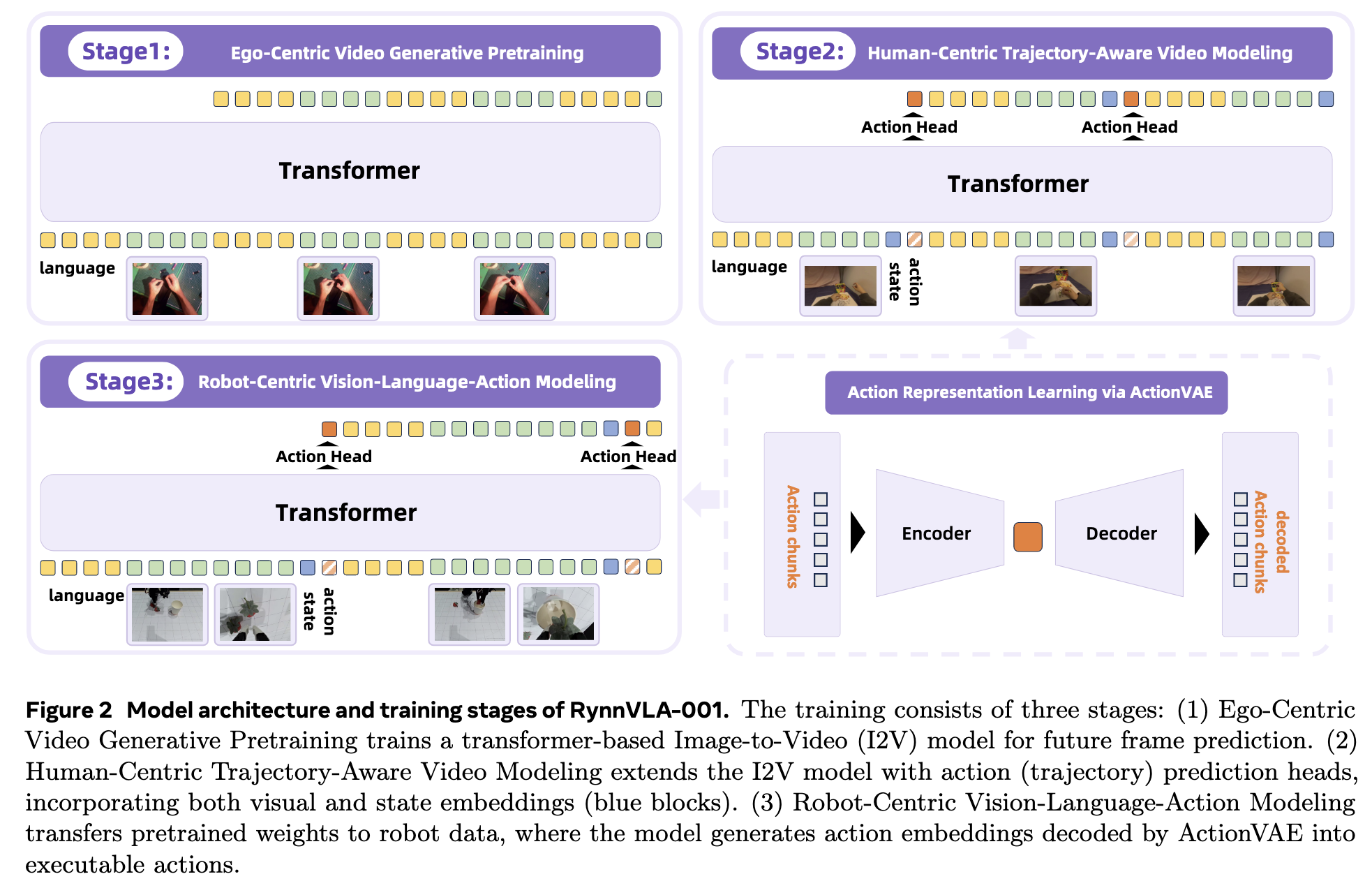
II. 方法论三大支柱
RynnVLA-001 的成功建立在三个紧密耦合的设计支柱之上:渐进式训练框架、作为动作表示核心的 ActionVAE、以及为机器人任务量身定制的 Transformer 架构与训练策略。
支柱一:渐进式三阶段训练框架
这是一个从“通用视觉理解”到“具体动作执行”的由粗到精的学习课程。
- Stage 1: Ego-Centric Video Generative Pretraining (通用世界模型学习)
- 目标: 学习物理世界的动态变化。
- 方法: 在 1200 万个人类第一视角视频上训练一个 Image-to-Video (I2V) 模型,任务是根据初始帧和文本描述,预测未来的视频帧。
- 产出: 一个对“手部操作如何引起世界变化”有基础视觉理解的 Transformer 主干网络。
- Stage 2: Human-Centric Trajectory-Aware Video Modeling (搭建“视觉-动作”桥梁)
- 目标: 将纯粹的视觉变化与产生该变化的运动轨迹关联起来。
- 方法: 这是一个多任务学习阶段。模型不仅要继续预测未来视觉帧,还要同时预测人类手腕的关键点轨迹。
- 产出: 一个理解了“视觉动态”与“动作意图”之间关系的、更面向动作的模型。
- Stage 3: Robot-Centric Vision-Language-Action Modeling (特定机器人适配)
- 目标: 将学到的通用知识适配到具体的机器人形态 (Embodiment) 上。
- 方法: 继承前序权重,在真实的机器人数据集上微调。主要任务是预测机器人动作,同时保留未来视觉预测作为辅助的正则化项,防止模型遗忘通用知识。
支柱二:ActionVAE - 动作表示的核心
ActionVAE 是实现平滑、连贯且高效动作生成的关键组件。
- 定义: 一个变分自编码器,其作用是将一段高维、连续的“动作块 (action chunk)” 压缩成一个低维、连续的“紧凑 (compact)”嵌入。
- “Compact”的深层含义:
- 低维度: 将复杂的动作序列(如 70 维)压缩至极低维度(如 8 维),简化了主模型的预测任务。
- 信息密集: 巨大的压缩压力(信息瓶颈)迫使 VAE 抓住动作的核心模式,过滤掉噪声。
- 结构化: VAE 的正则化项使得潜在空间平滑且连续,保证了相邻嵌入对应平滑过渡的动作。
- “Compact”的深层含义:
- 为何能学习“原子运动基元 (Atomic Motion Primitives)”: 这不是被直接教导的,而是涌现出的能力。信息瓶颈、潜在空间正则化以及训练数据中高频出现的重复性动作(如“伸出”、“抓取”)共同作用,迫使
ActionVAE发现并学习这些构成所有复杂任务的最基础、最有代表性的动作模式。 - “Embodiment-Specific”特性与可复用性:
ActionVAE是专机专用的,一个为A款机器人训练的 VAE 无法用于B款机器人。但其巨大优势在于,一旦为某款机器人训练好,它就掌握了该机器人的通用“动作词典”。未来,无论让该机器人学习何种新任务,都无需重训练ActionVAE,可直接用它来编码新任务的示教数据,极大提升了效率和复用性。 - 与 VQ-VLA 的对比: 这是一个重要的技术路线差异。
- RynnVLA (ActionVAE): 将动作编码为连续嵌入,在平滑的潜在空间中进行回归预测。
- VQ-VLA (VQ-VAE): 将动作离散化,编码为码本中的索引(整数ID)。它将困难的回归问题转化为更适合 Transformer 的分类问题,通过学习结构化的“动作词汇表”来提升表示精度。
支柱三:Transformer 架构与训练细节深度解析
- A. 输入序列的精巧设计
- 万物皆 Token: 无论是语言、视觉画面,还是机器人状态,都通过各自的编码器转换成统一的、离散的 Token 序列,这是 Transformer 处理多模态数据的基础。
- 语言-视觉交错 (Interleaving): 输入序列采用
[语言, 视觉_t, 语言, 视觉_t+1, ...]的格式。这是为了完美模拟机器人推理时的闭环流程。在每一步决策时,机器人都需要结合“当前所见”和“不变的目标”,这种训练方式让模型不断演练真实工作场景,使训练与推理无缝对齐。 <ACTION_PLACEHOLDER>的作用:- 它是一个直接给定的、非学习的特殊 Token。
- 作为触发器: 它的出现是一个明确的信号,命令模型:“现在,生成动作!”
- 作为信息组织者: 它的位置确保了模型在做决策时,能同时看到三类关键信息:高层目标 (Language), 当前场景 (Visual), 自身姿态 (State),模拟了智能体的情境化决策过程。
- B. 训练过程:自回归的“预测下一个 Token”
- 核心范式: 模型的唯一任务是根据到目前为止的所有 Token,来预测序列中的下一个 Token。
- 监督信号: 使用交叉熵损失 (Cross-Entropy Loss)。模型对下一个 Token 的预测是一个概率分布,该损失函数衡量这个分布与真实答案之间的差距,并以此来更新模型权重。
- 为何输出中也包含 Language 和 State?: 这是训练时的现象,源于自回归的训练范式。为了让模型学习完整的序列模式,它被要求预测所有类型的未来 Token。但在推理时,我们只关心
<ACTION_PLACEHOLDER>对应的动作输出,会提前终止生成过程。
- C. Transformer 的“魔法”:上下文感知与精确定位
- 上下文感知: 由于自注意力机制 (Self-Attention),Transformer 在计算任何一个位置
k的输出向量Vector_k时,都会让Token_k与其之前的所有 Token (Token_1到Token_k) 进行信息交互。这使得每一个输出表示都是上下文感知的,而非孤立的。 - 精确定位: 模型之所以知道哪个输出向量对应
<ACTION_PLACEHOLDER>,是基于严格的位置索引。Action Head模块被设计为只接收 Transformer 输出序列中与输入<ACTION_PLACEHOLDER>相同位置的那个向量。这是一个预先约定好的、简单而可靠的机制。
- 上下文感知: 由于自注意力机制 (Self-Attention),Transformer 在计算任何一个位置
IV. 推理过程:高效的闭环控制
- 输入: 模型接收当前
[语言, 视觉, state],并在末尾附上<ACTION_PLACEHOLDER>。 - 前向传播: 模型进行一次前向计算。
- 提取与解码: 只提取与
<ACTION_PLACEHOLDER>位置对应的输出向量,送入Action Head得到动作嵌入,再由ActionVAE的解码器解码为一段可执行的动作序列。 - 关键优化: 完全抛弃未来视觉帧的预测分支。这个分支在训练时是重要的正则化项,但在推理时既非必需又耗费算力。舍弃它极大地提升了决策速度。
- 循环: 机器人执行动作块,然后捕获新状态,重复此过程。
V. 总结与反思
RynnVLA-001 的精髓不在于单一的技术点,而在于其设计的整体性和逻辑的连贯性。从利用人类视频进行宏观物理知识的预训练,到通过轨迹感知建模建立视动关联,再到利用 ActionVAE 学习高效的动作表示,最后通过精巧的输入序列设计将训练与推理对齐,每一步都环环相扣,共同构建了一个从海量非结构化数据中汲取机器人智能的强大范例。
RynnVLA-001 Using Human Demonstrations to Improve Robot Manipulation
https://misaka0502.github.io/2025/09/24/RynnVLA-001/