Dreamer V3 Mastering Diverse Domains through World Models
Dreamer V3: Mastering Diverse Domains through World Models
深度学习笔记:解构DreamerV3——通用强化学习的基石
论文核心贡献: 本文提出了DreamerV3,一个基于世界模型的通用强化学习算法。其核心突破在于,使用单一固定超参数配置,在超过150个任务上展现了卓越的性能,超越了众多为特定领域精调的专家算法。其里程碑式的成就是,首次在不依赖人类先验知识(如数据或课程学习)的情况下,成功地从零开始在Minecraft中采集钻石,解决了AI领域的长期挑战。
一、 核心原理:基于世界模型的“学习-想象”双轨范式
DreamerV3的根本思想是将决策过程分解为两个并行且协同的阶段,以此来克服传统强化学习在数据效率上的瓶颈。
- 世界模型学习 (Learning the World Model): 智能体与真实环境进行交互,其首要目标并非直接学习策略,而是利用收集到的真实经验(图像、动作、奖励)来训练一个内部的世界模型。这个模型是智能体对现实世界运作规律的抽象理解和模拟。
- 在想象中学习 (Learning in Imagination): 一旦拥有了世界模型这个高效的“内部模拟器”,智能体便可以在其中进行大规模、高速的“想象”或“做梦”。它在这个安全且廉价的虚拟环境中生成海量轨迹,并利用这些想象数据来高效地训练其行为策略(Actor-Critic网络)。
这个范式的本质是一个学习杠杆:将一次昂贵、缓慢的真实交互,放大为成千上万次廉价、快速的有效学习。
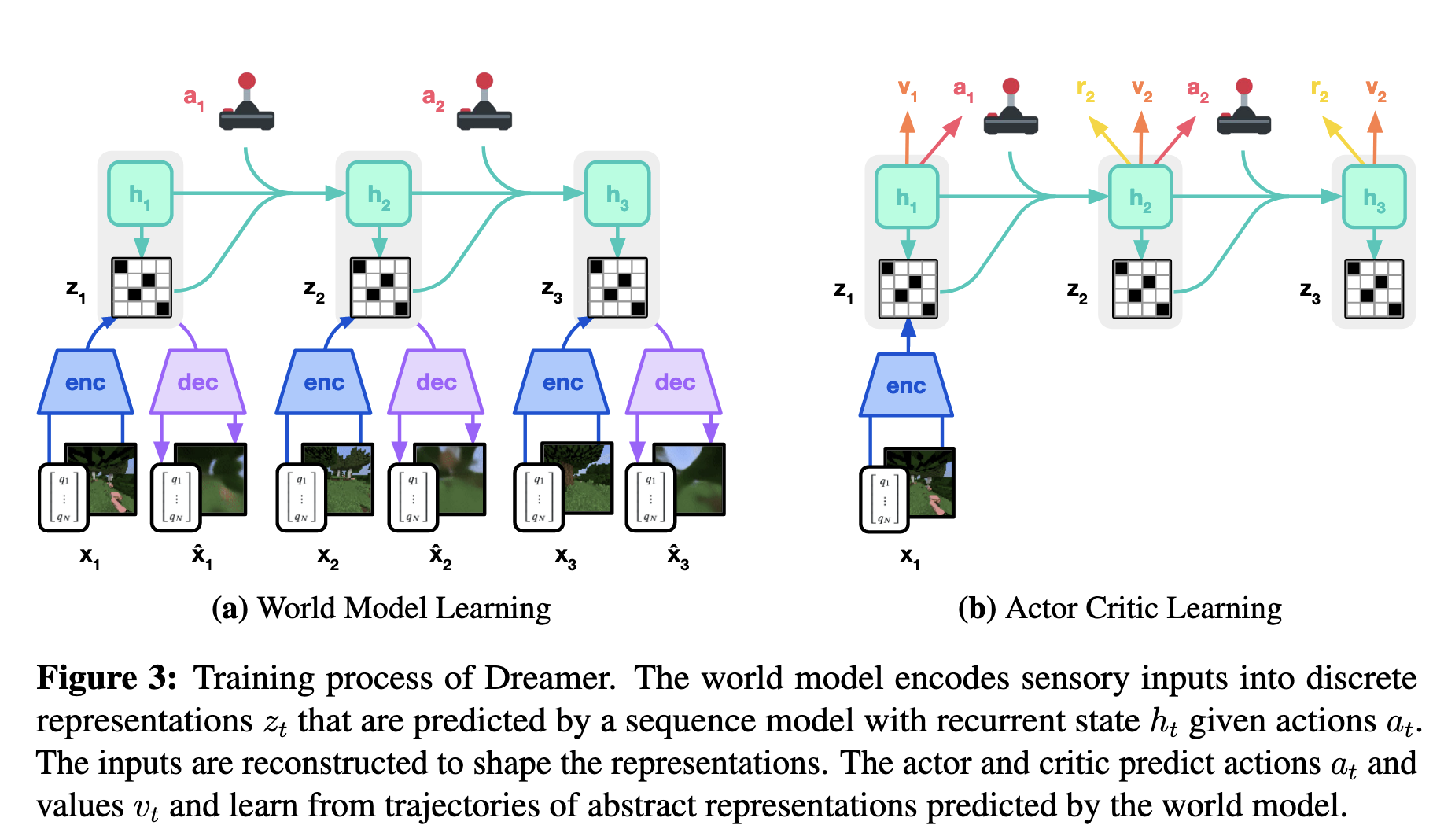
二、 方法论深度解析:算法的三大支柱
支柱I:世界模型 (World Model) - 内部模拟器
世界模型是整个框架的基石,其架构为循环状态空间模型 (Recurrent State-Space Model, RSSM),由多个专用神经网络模块构成。
- 网络架构:
- 编码器 (Encoder): 一个卷积神经网络 (CNN),负责将高维图像
压缩为低维特征。 - 循环模型 (Sequence Model): 一个带有块对角循环权重的GRU。这是模型的时间核心,它融合上一时刻的状态
和动作 ,来生成对当前时刻的确定性记忆 。 - 动态/表示模型 (Dynamics/Representation Model): 两个MLP,分别用于在有/无当前图像信息的情况下,预测随机潜在状态
的分布。 - 预测头 (Prediction Heads): 多个MLP和转置CNN (Decoder),负责从内部状态
中重构图像、预测奖励和回合结束标志。
- 编码器 (Encoder): 一个卷积神经网络 (CNN),负责将高维图像
支柱II:评论家网络 (Critic) - 分布式价值预测器
评论家的学习完全在世界模型生成的想象轨迹上进行。
- 核心创新:为何预测分布而非单值?
- 传统Critic预测回报的期望值,丢失了风险和不确定性信息。
- DreamerV3的Critic预测回报的完整概率分布,能够捕捉回报的多模态特性(例如,低概率的高额奖励),并为学习提供更稳定、更丰富的信号。
- 实现细节:TwoHot编码与交叉熵损失
- 离散化: 将连续的回报空间离散化为一系列固定的“桶”(Bins)。
- TwoHot编码: 将一个连续的目标回报值
,通过线性插值的方法,编码成一个在相邻两个桶上有非零权重的“软”目标概率分布 。 - 损失函数:
,即计算目标分布 和网络预测分布 之间的分类交叉熵。
- 关键优势:解耦梯度与目标尺度
- 该损失函数只关心概率的匹配程度,而与桶所代表的实际数值无关。这使得无论回报是0.1还是10000,梯度都能保持在稳定范围内,是实现跨领域稳定学习的核心秘诀。
支柱III:行动者网络 (Actor) - 智能策略
行动者同样在想象轨迹中学习。
- 损失函数:
(学习的力度): 这是经过归一化的优势函数 。 (stop_gradient) 确保梯度只流向Actor,不影响Critic。 (学习的方向): 策略的对数概率。与优势函数相乘,实现“奖励好行为,惩罚坏行为”的策略梯度学习。 (探索的激励): 熵正则化项,鼓励策略保持随机性以进行探索。
三、 成功的秘诀:一系列精巧的鲁棒性技术
DreamerV3的通用性并非来自单一思想,而是源于一套协同工作的、旨在提升鲁棒性的工程杰作。
- 智能归一化 (
): - 问题: 传统方法归一化优势函数,在稀疏奖励环境中会不成比例地放大评论家网络的预测噪声,导致探索停滞。
- 解决方案: DreamerV3归一化回报。其归一化除数为
,其中 是用第5和第95百分位数之差稳健估计的回报范围。 - 效果: 在奖励密集时(S>1),正常缩放;在奖励稀疏时(S<1),分母被锁定为1,有效抑制了噪声放大,让学习重点自动从“利用”转向“探索”。
- 稳定的数值处理 (
/ ): - 问题: 奖励、回报等数值尺度变化极大,且有正有负,直接用于MSE损失会导致梯度爆炸。
- 解决方案: 采用对称对数变换
及其逆变换。它在不丢失信息、不引入非平稳性的前提下,将所有目标值压缩到一个稳定的空间进行学习。它优于裁剪、动态归一化和R2D2中提出的非对称变换等替代方案。
- 稳定的目标更新 (EMA):
- 问题: 评论家的学习目标依赖于自身的预测,形成“追逐自己尾巴”的不稳定循环。
- 解决方案: 采用目标网络,其参数是主网络参数的指数移动平均 (EMA)。这为评论家提供了一个缓慢更新的、稳定的学习目标。同样,回报范围
的计算也使用EMA进行平滑,以抵抗批次间的波动。
四、 核心疑问解答与训练流程
- 世界模型和Actor-Critic是同时训练的吗?是的,同时且并发。 在每个训练步骤中,世界模型、Actor和Critic的梯度被一同计算,并通过一次优化器更新应用。这种协同进化至关重要,保证了世界模型与策略的探索步伐保持一致,避免了模型陈旧问题。
- 训练数据的来源是真实还是想象?两者都是,且分工明确。
- 世界模型的学习直接由回放缓冲区中的真实经验驱动,以保证其不与现实脱节。
- Actor-Critic的学习完全在由世界模型生成的想象轨迹上进行,以实现数据效率的巨大提升。
- 既然需要真实交互,为何还要多此一举用世界模型?为了压倒性的效率提升。 世界模型是“学习的放大器”。
- 数据效率: 将一次昂贵的真实交互,放大为成千上万次廉价的内部学习,极大减少了对真实样本的需求。
- 计算速度: 在GPU上进行并行的神经网络前向传播(想象),远比运行通常由CPU主导且难以并行的真实环境模拟要快几个数量级。
- 偏差管理: 通过持续校准、短期想象和学习抽象表示,DreamerV3有效地将模型的预测偏差控制在可接受范围内。
五、 总结
DreamerV3的成功并非偶然。它建立在基于模型的强化学习这一强大范式之上,并通过一套精心设计的、以鲁棒性为核心的技术体系,系统性地解决了该范式在实践中面临的诸多挑战。从解耦梯度与目标尺度的TwoHot损失,到智能抑制噪声的回报归一化,再到稳定数值的symlog变换,每一个细节都旨在构建一个能够“即插即用”的通用决策引擎。
这篇工作雄辩地证明,学习一个关于世界如何运作的内部模型,是通往更通用、更高效人工智能的一条充满希望的康庄大道。
Dreamer V3 Mastering Diverse Domains through World Models
https://misaka0502.github.io/2025/09/24/Dreamer-V3/