Learning to Act Anywhere with Task-centric Latent Actions
论文地址:Learning to Act Anywhere with Task-centric Latent Actions
这篇论文的核心目标是解决当前机器人学习领域的一个重大挑战:如何创建一个通用(Generalist)的机器人策略,使其能够利用互联网上海量的、多样化的、无动作标签的视频(例如人类活动视频),并在不同的机器人(Embodiment)和不同的任务上高效工作。
一、核心问题与现有方法的局限
- 数据依赖性强:传统方法严重依赖于带有精确动作标签(如机器人关节角度、末端执行器坐标)的专家演示数据。这种数据的收集成本高昂,且难以规模化。
- 泛化能力差:在一个机器人上训练的模型很难直接迁移到另一个形态、动作空间完全不同的机器人上。
- 无法利用无标签数据:互联网上有海量的视频资源(如YouTube、Ego4D数据集中的第一人称视频),这些视频包含了丰富的关于物理世界交互的知识,但因为没有机器人可用的动作标签,传统方法无法利用它们。
- 任务无关动态的干扰:真实世界的视频(无论是机器人录制的还是人类录制的)充满了与任务无关的“噪声”,例如相机晃动、背景物体移动、光照变化等。这些噪声会严重干扰模型的学习。
二、UniVLA的核心思想与贡献
UniVLA提出了一种创新的解决方案,其核心思想是:不直接学习底层、具体的机器人动作,而是学习一个统一的、抽象的、任务中心的“潜在动作空间”(Latent Action Space)。
这个潜在动作空间就像一种通用的“机器人动作语言”。
- 统一与通用:无论是A机器人的抓取、B机器人的导航,还是人类视频里的开关门,都可以被“翻译”成这种通用语言中的一个“词汇”或“句子”(即潜在动作序列)。
- 任务中心 (Task-centric):这种语言只描述与完成任务强相关的动态(例如“手正在伸向杯子”),并主动忽略相机晃动等无关干扰。
通过这种方式,UniVLA可以将所有不同来源的视频数据都转换成这种统一的语言格式进行学习,从而训练出一个极其强大的通用策略。
三、方法详解:三步走策略
UniVLA的实现分为三个关键阶段:
- 任务中心潜在动作学习 (Task-centric Latent Action Learning):这是最关键的创新。此阶段的目标是从无标签视频中,学习到一个高质量的“动作词典”(Codebook)。
- 通用策略的预训练 (Pretraining of Generalist Policy):使用上一步得到的“动作词典”去标注海量视频数据,然后用这些数据训练一个大型的视觉-语言-动作模型。
- 部署阶段的解码 (Post-training for Deployment):将预训练好的通用模型,通过一个轻量级的解码器适配到具体的机器人上,将抽象的“动作语言”翻译成真实的机器人控制信号。
下面我们详细解析每个阶段。
阶段一:任务中心潜在动作学习 (这是本文的技术核心)
这个阶段的目标是从成对的视频帧
1. 模型架构 (见论文图2)
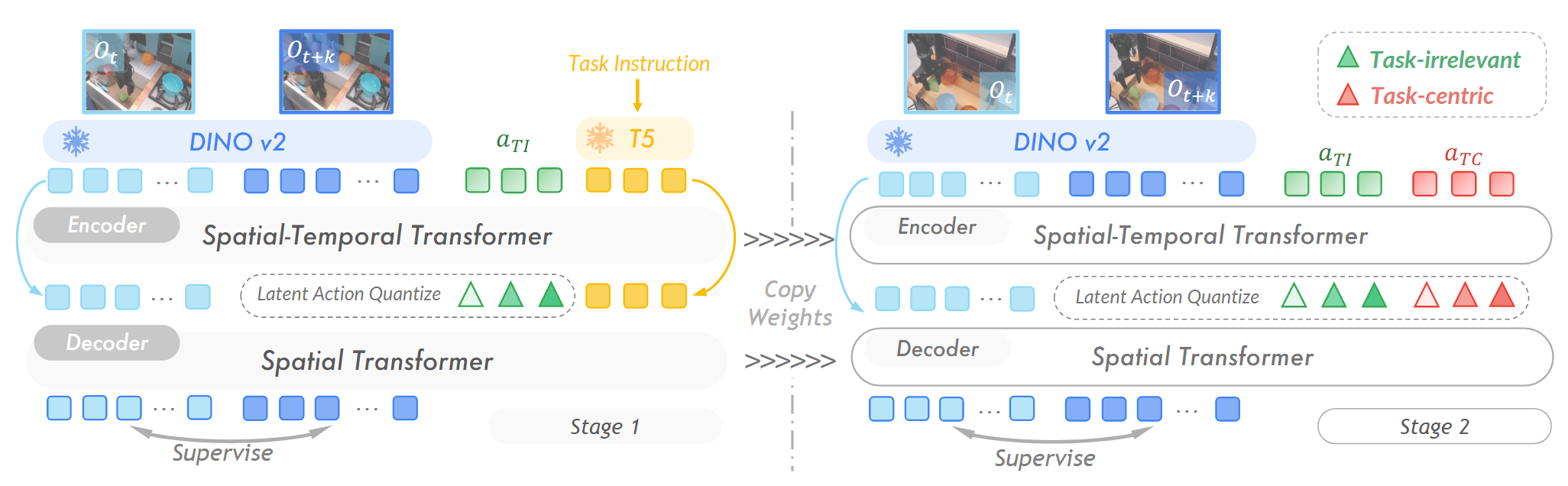
- 输入: 一对DINOv2特征图
。注意:论文不使用原始像素,而是使用预训练好的DINOv2模型提取的特征。这很重要,因为DINOv2特征包含了丰富的物体和语义信息,比原始像素更鲁棒。 - 编码器 (Encoder): 扮演逆向动力学模型(IDM) 的角色。它的任务是“猜测”:给定初始状态
和目标状态 ,中间发生了什么“动作”?它会输出一个连续的潜在动作向量 。 - 量化层 (Quantization): 使用VQ (Vector Quantization) 技术,将连续的
映射到离散的“动作词典”(Codebook)中最近的一个“单词” 。这个词典就是我们最终想要的。 - 解码器 (Decoder): 扮演前向动力学模型(FDM) 的角色。它的任务是“预测”:给定初始状态
和一个“动作单词” ,未来的状态 应该是怎样的? - 训练目标: 最小化解码器预测的未来特征
和真实的未来特征 之间的差异(重构损失)。
2. 创新的两阶段训练法 (The Decoupling Trick)
这是为了解决“任务无关动态干扰”问题的关键。
训练第一阶段:学习“任务无关”动态
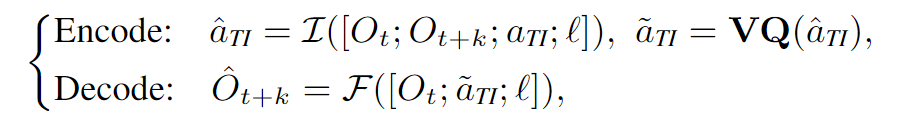
- 在训练上述VQ-VAE架构时,把语言指令
(例如“把杯子放到盘子里”) 作为解码器的额外输入。 - 原理: 论文认为,当解码器被告知了任务的高层目标(通过语言指令),那么有限容量的动作词典
就被迫去编码那些语言指令无法描述、但重构下一帧又必须的信息。这些信息恰好就是任务无关的动态,如光照变化、相机晃动等。这一阶段学习到的动作词典被称为 (Task-Irrelevant)。
- 在训练上述VQ-VAE架构时,把语言指令
训练第二阶段:学习“任务中心”动态
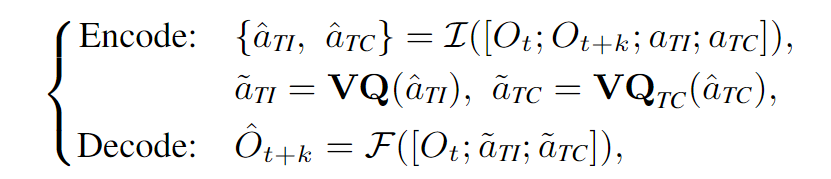
- 冻结第一阶段训练好的所有参数和
词典。 - 引入一个全新的、可训练的动作词典,称为
(Task-Centric)。 - 现在,编码器同时输出两个潜在动作,分别送入
和 词典。解码器也同时接收来自这两个词典的输出 和 来重构下一帧。 - 原理: 由于任务无关的动态已经被冻结的
模块“解释”掉了,新引入的 模块为了最小化重构误差,就必须去学习和编码剩下的、无法被解释的动态——这正是智能体自身为了完成任务而产生的动作。 - 最终成果: 经过这个阶段,我们就得到了一个高质量的、只包含任务核心动作的词典
。从此,任何一段视频(无论来源)都可以被这个模型处理,输出一串 中的“动作单词”序列,相当于给视频自动打上了统一的、高质量的动作标签。
- 冻结第一阶段训练好的所有参数和
阶段二:通用策略的预训练
这个阶段的目标是训练一个能理解“在什么场景下,根据什么指令,应该执行哪个潜在动作”的大脑。
- 模型架构: 使用一个强大的预训练视觉-语言模型 (VLM),如论文中提到的 Prismatic-7B。
- 训练数据: 将海量视频(机器人演示、人类视频等)通过阶段一的模型,全部转换成
的数据对,其中 就是潜在动作序列。 - 训练方法: 采用自回归 (Auto-regressive) 的方式进行训练,这与GPT等语言模型的训练方式完全一样。
输入: 当前观测
,任务指令 ,以及已经预测出的潜在动作前缀 。 输出: 下一个最可能的潜在动作
的概率分布。 优化目标: 最小化负对数似然。通俗讲,就是最大化模型预测出正确潜在动作序列的概率。
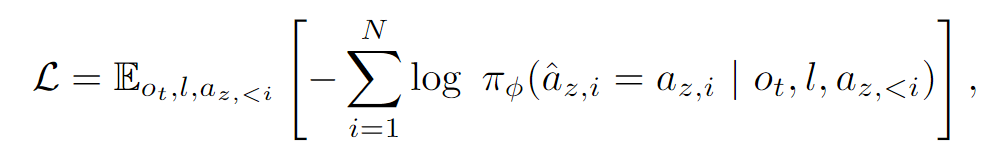
阶段三:部署阶段的潜在动作解码
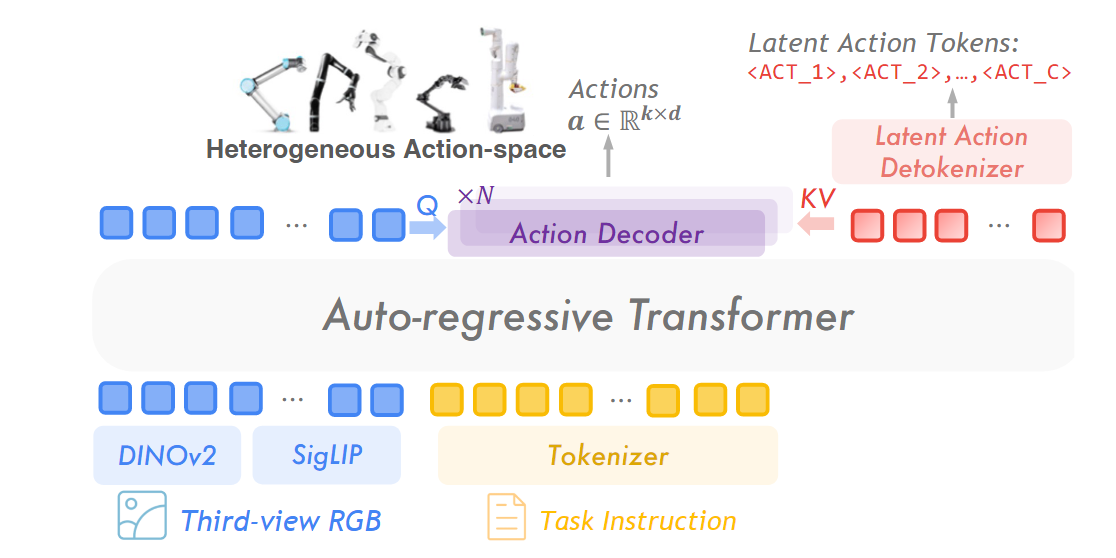
现在我们有了一个能输出抽象“动作单词”的通用策略,最后一步是将其应用到真实机器人上。
问题: 策略输出的是“动作单词”,但真实机器人需要的是具体的控制信号,比如
。 解决方案: 训练一个轻量级的动作解码器 (Action Decoder)。
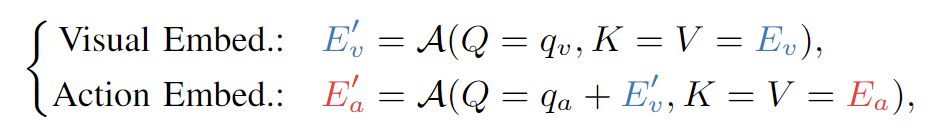
输入: VLM输出的潜在动作
的 embedding,以及VLM的视觉特征 。 输出: 目标机器人对应的底层动作空间。
训练: 在少量对应机器人的专家数据上进行微调 (Fine-tuning)。因为大部分“思考”的工作都由预训练好的VLM完成了,这个解码器只是做一个简单的“翻译”,所以需要的特定数据很少,训练成本很低。
详细过程:

总结
UniVLA通过一个巧妙的两阶段解耦学习框架,成功地从无标签视频中学习到了一个任务中心的、统一的潜在动作空间。然后,它利用这个统一的动作表示,将机器人控制问题转化为了一个大规模的序列预测问题,并用强大的VLM进行预训练。最后,通过一个轻量级的解码器,实现了对不同物理机器人的高效适配。这种方法极大地提升了机器人策略的泛化能力、数据利用效率和可扩展性,是通向通用机器人的一条非常有前景的路径。