OpenVLA(An Open-Source Vision-Language-Action Model)
一、背景
1.机器人操作策略的弱点:
- 无法在训练数据之外泛化,即使有些方法能够将操作行为推广到不同的初始条件(比如对象位姿),但仍然缺少鲁棒性,难以应对数据集中不存在的情况
- 相比LVLM,机器人操作任务数据集的数据量较少,即使最大的机器人操作数据集也只有100k-1M个演示(Open X-Embodiment)
2.当前VLA的通病
- 现存的很多模型都是闭源的,对模型架构、训练过程和数据混合的可见性有限
- 现有的工作没有将VLA部署和适应不同机器人、环境和任务的实践
- 消费级GPU跑不起
3.视觉语言模型的优势
- 现存的LVLM几乎都是在巨大规模的互联网数据上训练的,且得益于LLM超强的序列建模能力,LVLM具备较强的泛化能力
- 借助VLM构建机器人策略,有机会推广更多的对象、场景和任务等
二、主要创新点
- 模型架构和预训练组件
- 以往许多工作通常是将一些预训练的组件(如视觉编码器等)和机器人策略缝合,而OpenVLA采用的是更加端到端的方法,VLM将actions视为词表中的tokens,直接对VLM进行微调以生成机器人动作(没有采用传统意义上的策略)
- 在多种机器人上推广(Aloha、franka等)
- 参数量少,通过微调和量化,在消费级GPU上也能运行
- 7B参数(相对于其他VLA很少)
- 对多种微调和量化方法进行了实验,OpenVLA可以在保持性能的同时进一步降低硬件要求
- 开源
三、模型架构
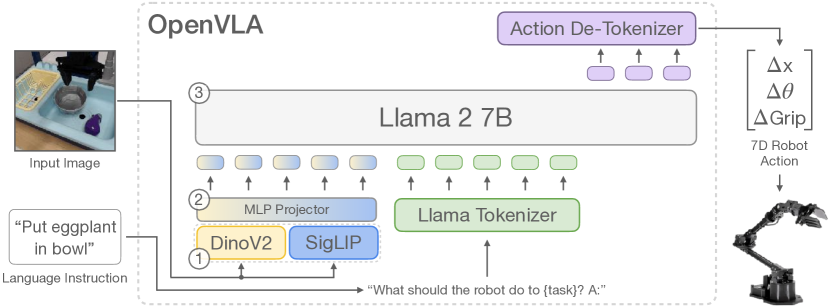
主要组件:视觉编码器、投影器、LLM主干。
OpenVLA采用的是Prismatic VLM,它的视觉编码器由两部分组成:DinoV2和SigLIP。
论文称加入DinoV2有助于改进空间推理,对机器人控制特别有用,比单独的SigLIP性能更好。
视觉输入经过双视觉编码器提取特征后经过MLP Projector,语言输入则经过Llama Tokenizer,两者被投影到各自的向量空间,共同输入给Llama 2,输出的Tokens经过去标记器后得到机器人动作(相对位姿和夹爪动作)。
四、训练
为了使VLM的语言模型主干能够预测机器人动作,OpenVLA将连续的机器人动作映射到语言模型的tokenizer使用的离散tokens,具体来说:
对每个动作维度(假设N维),设置256个箱(bins),箱的宽度取决于均匀划分训练数据中动作数值的第1和第99百分位数之间的间隔。不采用最小值-最大值来分箱,是为了防止少数离群点拉宽区间,导致大多数正常的动作被挤在几个很少的箱子里。
将机器人动作的每个维度(假设N维)分别离散到256个箱(bins)中的一个。
使用这种离散化,最后会获得N维机器人动作的N的离散整数\(\in [0,255]\)。
将动作被处理为一系列tokens后,采用next-token prediction进行训练,目标是减少动作token上的交叉熵损失。实际上LLM最后输出的是每个动作落在每个箱子里的概率,然后将这些箱子对应的动作组成动作序列。
OpenVLA采用Open X-Embodiment提供的数据集,和他们自己收集的一些额外的数据集混合
最终的OpenVLA模型在64个A100 GPU的集群上训练14天,或总共21500个A100小时。在推理过程中,OpenVLA在以bfloat16精度加载(即,没有量化)时需要15GB的GPU内存,并在一个NVIDIA RTX 4090 GPU上以大约6Hz的频率运行
五、实验结果
1.在各种机器人上的实验结果
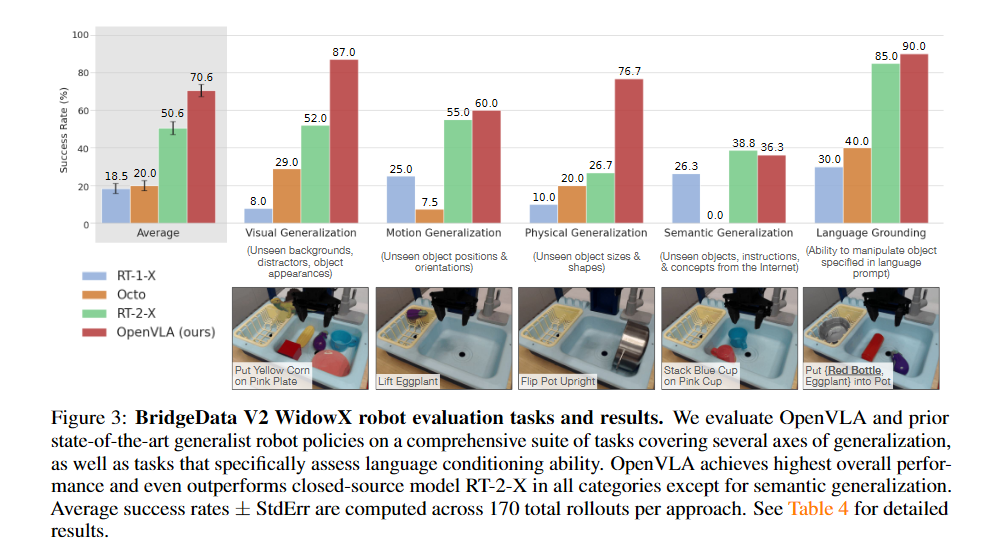
WidowX——BridgeData V2
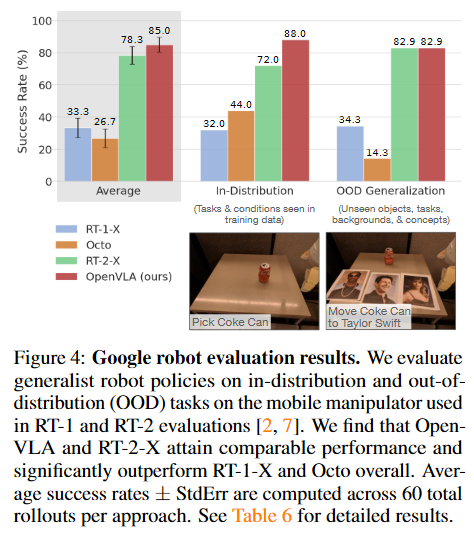
Google robot evaluation results.
Adapting to new robot setups.
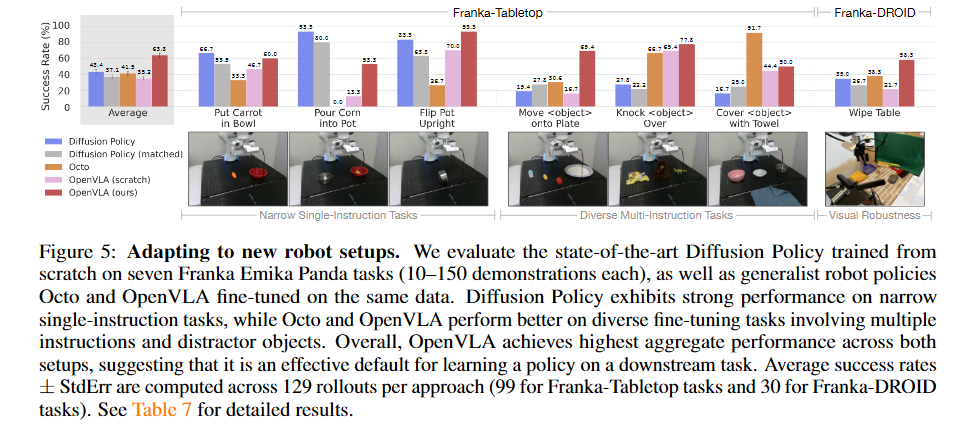
2.与Diffusion Policy的对比
这里特别提一下实验中的DP基线。实验设置了两种DP基线,一种是正常的按照预测动作序列并开环执行动作序列的DP,其观测也是常见的图像+本体感知的类型,这个策略是实验中唯一一个预测绝对笛卡尔坐标的方法。另一种被记为Diffusion Policy(matched),只输出单个动作,而且观测只包含图像,没有本体感知。
论文中对DP和VLA的表现对比总结如下:
我们发现,在“将胡萝卜放入碗中”和“将玉米倒入锅中”等较窄的单指令任务上,两个版本的扩散策略都与通用策略Octo和OpenVLA相媲美或表现更好,但预训练的通用策略在涉及场景中的多个对象并需要语言调节的更多样化的微调任务中表现更好。
对于更窄但高度灵巧的任务,扩散策略仍然显示出更平滑、更精确的轨迹;结合扩散策略中实现的动作分块和时间平滑,可能有助于 OpenVLA 达到相同的灵巧程度,并且可能是未来工作的有希望的方向。
六、微调
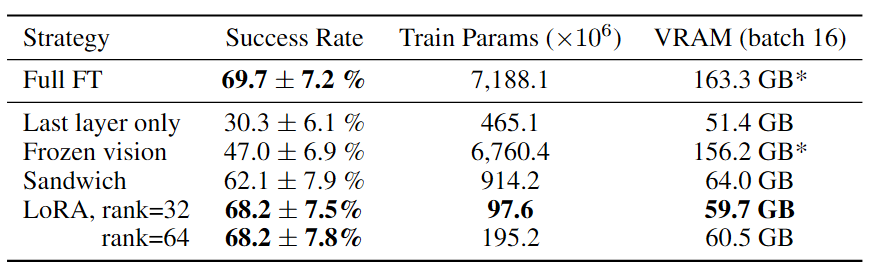
文中对几种不同的微调方式进行实验,包括:
- Full FT:完全微调(所有参数)
- Last layer only:仅微调LLM主干的最后一层和token嵌入矩阵
- Frozen vision:冻结视觉编码器,微调其他所有参数
- Sandwich:微调视觉编码器、token嵌入矩阵和LLM主干最后一层
- LoRA:Low-Rank Adaptation,将特定层的参数矩阵分解为两个小矩阵,减少参数更新量
- 不同微调方式的显存占用和性能
- 仅微调网络的最后一层或冻结视觉编码器会导致性能不佳,这表明进一步调整视觉特征以适应目标场景至关重要。
- “三明治微调”实现了更好的性能,因为它微调视觉编码器,并且它消耗更少的GPU内存,因为它不会微调整个LLM主干。
- LoRA在性能和训练内存消耗之间实现了最佳的折衷。
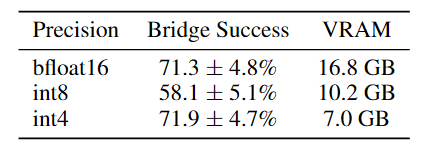
七、量化
原始精度和两种不同量化方式在BridgeData V2上的比较:
推理速度:
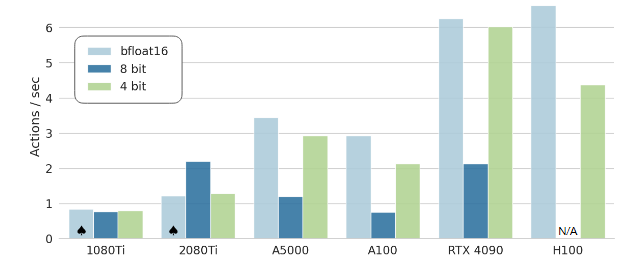
结论基本上是: bfloat16和int4量化的性能相当,但是int4量化的显存占用只有不到bfloat16的一半;int8最差,尽管显存占用少于bloat16,但推理速度却是最慢的,查了下资料,可能是由于int8的硬件支持不如其他两个。
八、局限
文中总结了四点局限性
- OpenVLA只支持单个图像观察,感知输入的类型需要扩展
- 推理速度还是不够快
- 尽管泛化能力强,但是成功率并不算高,对各种测试任务成功率基本都在90%以下(相比之下,一些针对特定任务的学习策略尽管泛化性欠佳,但是成功率很高,比如DP+残差强化学习)
- VLA的硬件要求高,许多问题未得到充分探索,如VLM的大小对VLA的影响、训练数据的混合等等