多智能体强化学习(MARL)值函数分解——从VDN到QMIX
一、MARL中的难点
1、部分可观察
当
比如StarCraft II:
Partial observability is achieved by the introduction of unit sight range, which restricts the agents from receiving information about allied or enemy units that are out of range. Moreover, agents can only observe others if they are alive and cannot distinguish between units that are dead or out of range.
2、不稳定性
在multi-agent环境中,由于
总结造成不稳定性的原因主要是两点:
- 部分可观察的场景使得
下对应的 有很多 - 其他
也在学习,策略不断在变化,选择的动作也在不断变化
因此,同样的
二、为什么要进行值函数分解
主要的原因就在于,每个智能体只能在自己的角度去观测和决策,无法站在全局的角度去观测和决策,从而无法学到全局的最优策略。为了解决这个问题,学者提出使用𝐶𝑒𝑛𝑡𝑟𝑎𝑙𝑖𝑧𝑒𝑑 𝑇𝑟𝑎𝑖𝑛𝑖𝑛𝑔 𝐷𝑒𝑐𝑒𝑛𝑡𝑟𝑎𝑙𝑖𝑧𝑒𝑑 𝐸𝑥𝑐𝑢𝑡𝑖𝑜𝑛(𝐶𝑇𝐷𝐸)的方法,将条件限制放松,允许
一个直观的想法是去训练一个全局的
综上,仅仅使用
三、VDN(Value Decomposition Networks)
VDN的思想很简单,就是将
其中
其中
通过这种方法,梯度就会通过
四、QMIX(Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning)
1、VDN的缺点
VDN是将所有的
2、QMIX的思想
QMIX也是基于CTDE和DQN的方法,其与VDN最主要的区别就在于QMIX是利用一个神经网络(称为“混合网络”)去近似
Key to our method is the insight that the full factorisation of VDN is not necessary in order to be able to extract decentralised policies that are fully consistent with their centralised counterpart. Instead, for consistency we only need to ensure that a global argmax performed on
yields the same result as a set of individual argmax operations performed on each 我们方法的关键是认识到,为了能够提取与集中式策略完全一致的去中心化策略,不需要对 VDN 进行完全分解。相反,为了保持一致性,我们只需要确保在 上执行的全局 argmax 产生与在每个 上执行的一组单独的 argmax 操作相同的结果
由此引出QMIX中最核心的一个约束:
这也是论文题目中“Monotonic”一词的体现,通过这个约束来保证
而这个约束是通过限制混合网络的每层权重
2.1 算法大框架 —— 基于 AC 框架的 CTDE(Centralized Training Distributed Execution) 模式
多智能体强化学习(MARL)训练中面临的最大问题是:训练阶段和执行阶段获取的信息可能存在不对等问题。即,在训练的时候我们可以获得大量的全局信息(事实证明,只有获取足够的信息模型才能被有效训练)。
但在最终应用模型的时候,我们是无法获取到训练时那么多的全局信息的,因此,人们提出两个训练网络:一个为中心式训练网络(Critic),该网络只在训练阶段存在,获取全局信息作为输入并指导 Agent 行为控制网络(Actor)进行更新;另一个为行为控制网络(Actor),该网络也是最终被应用的网络,在训练和应用阶段都保持着相同的数据输入。
AC 算法的应用非常广泛,QMIX 在设计时同样借鉴了 AC 的 “中心式网络” 和 “分布式执行器” 的想法,整个网络包含了 Mixing Network(类比 Critic 网络)和 Agent RNN Network(类比 Actor 网络)
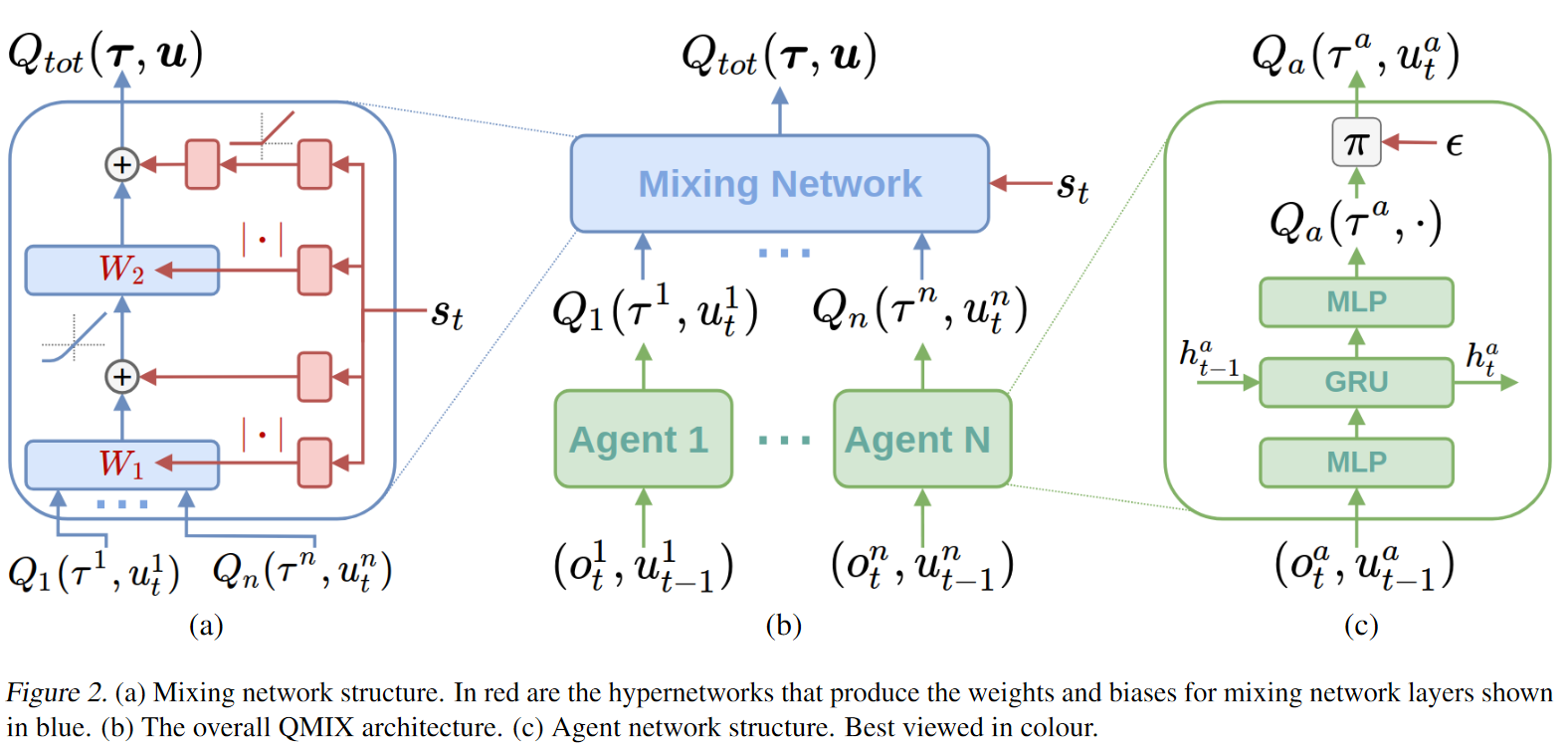
2.2 Agent RNN Network
QMIX 中每一个 Agent 都由 RNN 网络控制,在训练时可以为每一个 Agent 个体都训练一个独立的 RNN 网络,同样也可以所有 Agent 复用同一个 RNN 网络。
RNN 网络一共包含 3 层,输入层(MLP)→ 中间层(GRU)→ 输出层(MLP)
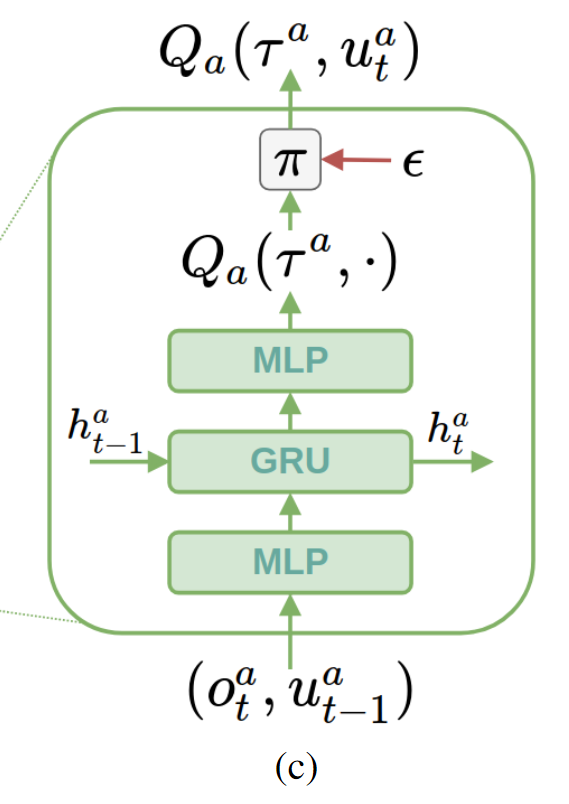
2.3 混合网络
混合网络同时接收
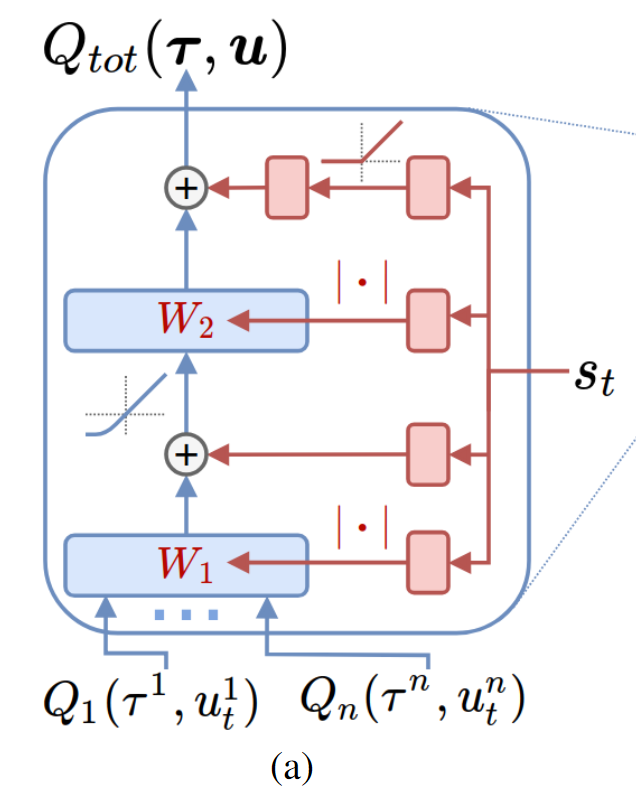
混合网络使用前馈神经网络结构。
前面说到,混合网络要满足式(3),如果𝒔和
- hypernetworks: 接收全局状态
,生成蓝色网络中的神经元权重(weights)和偏差(bias)。 - 推理网络:接收所有 Agent 的行为效用值
,并将参数生成网络生成的权重和偏差赋值到网络自身,从而推理出全局 。
在这里可以看到hypernetworks输出权重的时候会加一个绝对值使权重不小于0,这就是前面说的为了保证式(3)成立,保证局部最优动作就是全局最优动作。
2.4 模型更新流程
本质上和VDN是一样的,都是根据DQN的方法去优化